Large Language Model (LLM) Evaluation is a central part of the process of deploying and enhancing LLM-powered applications. In this post, we'll explore the methodologies of LLM evaluation, splitting everything between two primary categories: LLM-as-a-Judge and Human-as-a-Judge.
LLM-as-a-Judge Evaluation
Overview
LLM-as-a-Judge evaluation leverages the capabilities of LLMs to assess the outputs of other LLMs. This method mimics human-like assessment but the work is done by Large Language Models.
How It Works
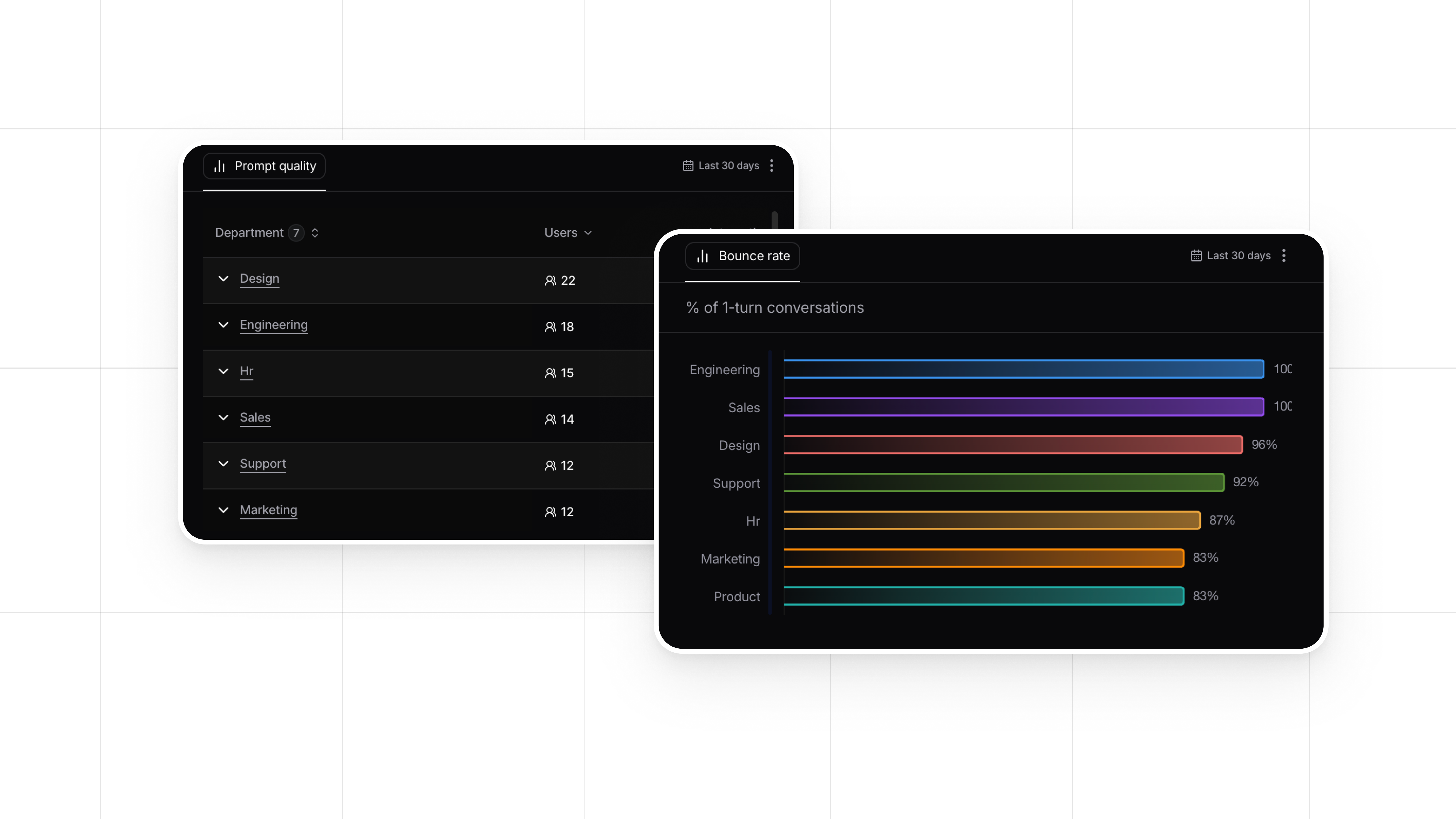
- Identify Evaluation Criteria: Determine what characteristics you want to evaluate, such as hallucination, toxicity, accuracy, or another trait. Utilize pre-tested evaluators for common assessment criteria.
- Craft Your Evaluation Prompt: Write a prompt template that guides the evaluation process. This template should define the variables needed from both the initial prompt and the LLM's response to effectively assess the output.
- Select an Evaluation LLM: Choose a suitable LLM for conducting your evaluations. The chosen model should align with the specific evaluation needs.
- Generate Evaluations and View Results: Execute the evaluations across your dataset. This process allows for comprehensive testing without the need for manual annotation, enabling quick iteration and prompt refinement.
Advantages
- Consistency: Provides uniform assessment criteria used industry wide.
- Initial speed: Accelerates the iteration process for refining LLM prompts and responses even before there’s any real users.
Human-as-a-Judge Evaluation
Overview
The Human-as-a-Judge category, as presented here, focuses on evaluation methods where human input is crucial for assessing LLM outputs. This includes explicit human judgment as well as implicit user feedback derived from real interactions. By coining this term, closely similar to concepts known as User-Based LLM Evaluation or Human Evaluation, we aim to centralize the human perspective in the evaluation process, ensuring that user satisfaction is a primary metric that LLM developers should focus on.
Methods and Metrics
- Human Evaluation (aka Vibe Checking): Involves domain experts or representative end users manually assessing the quality of the model's outputs. This includes evaluating aspects like fluency, coherence, creativity, relevance, and fairness.
- Tactics:
- Review outputs generated by the LLM.
- Rate outputs based on specific criteria relevant to the application.
- Use feedback to adjust and refine the model.
- Tactics:
- A/B Testing: Conducting controlled experiments where different versions of an LLM feature are tested with users to determine which performs better.
- Tactics:
- Divide users into control and treatment groups.
- Deploy different versions of the LLM feature to each group.
- Compare performance metrics such as user satisfaction and engagement.
- Tactics:
- Crowdsourcing: Utilizing a large number of individuals to evaluate LLM outputs. This method can quickly generate substantial feedback, providing diverse perspectives.
- Tactics:
- Distribute evaluation tasks to a crowd of users.
- Collect and aggregate feedback to assess model performance.
- Use aggregated data to refine and improve the model.
- Tactics:
- Explicit User Feedback: Collecting feedback directly from users who interact with LLM applications in real-world scenarios. This feedback can include thumbs up/down, ratings, and comments.
- Tactics:
- Ask users to leave explicit feedback after interacting with your LLM.
- Manually analyze qualitative explicit feedback to identify areas for improvement.
- Tactics:
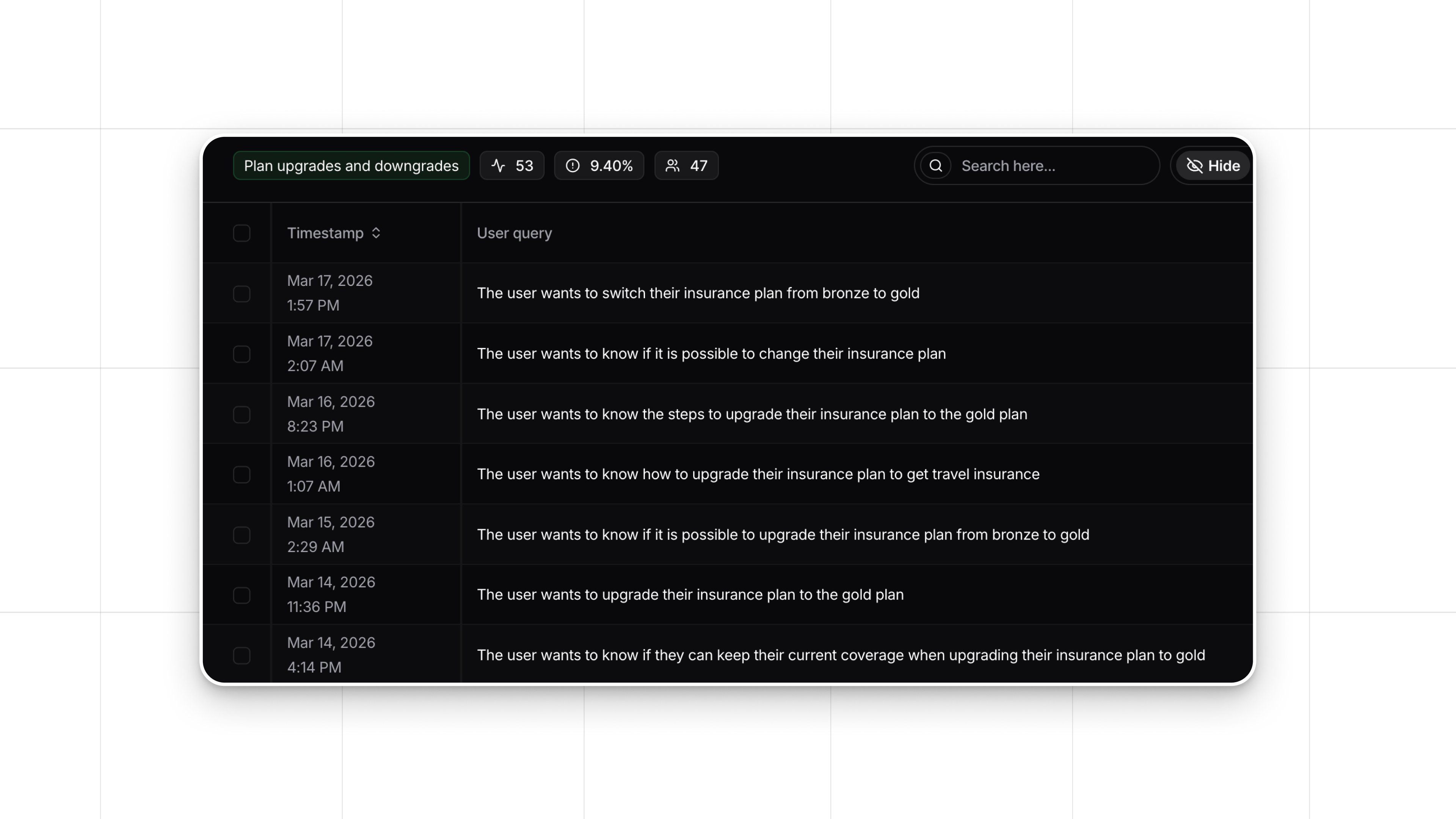
- Implicit User Feedback and Engagement: This is indirect feedback gathered from user prompts, behavior, and interactions with the application.
- Tactics:
- Monitor user interactions with LLM features.
- Track engagement metrics such as acceptance rates, conversation length, and user retention.
- Automatically analyze and detect implicit feedback to identify areas for improvement, such as user warnings and positive experiences.
- Tactics:
Advantages
- Scalability: With implicit user feedback evaluation, this method can be scaled as user activity increases. It collects extensive feedback based on real user interactions without needing continuous manual effort.
- Real User Experiences: Provides insights based on actual user interactions, ensuring that the evaluation reflects real-world performance.
- Nuanced Feedback: Captures the subtleties of human language and interaction that automated systems might miss.
Conclusion
Both Human-as-a-Judge and LLM-as-a-Judge evaluations are essential for a comprehensive assessment of LLMs. Human-as-a-Judge methods provide nuanced, qualitative insights that capture the subtleties of human language and interaction. Human evaluation captures the experience and satisfaction of users and uses the findigs to improve the model. LLM-as-a-Judge methods offer evaluations that ensure models meet performance standards across uses cases and according to a range of pre-set criteria. By combining these approaches, we can achieve robust and diverse evaluation and continuous improvement of LLMs, aligning them with real user needs. The promise of scaling real human feedback through continuous monitoring of user interactions and prompts is particularly exciting, offering a path to ever-more effective and aligned AI systems.
About Nebuly
Nebuly is committed to help teams build better LLM-based products with a user-centric approach. We assist companies in gathering, analyzing, and acting on valuable user feedback, both explicit and implicit. If you're interested in optimizing your AI solutions, we'd love to chat. You can schedule a demo meeting with us, HERE!