.png)
When working with Large Language Models (LLMs), understanding how to evaluate their outputs effectively is crucial. Whether you're deploying an LLM for a chatbot, content generation, or other applications, you need to ensure that the results are reliable, accurate, and useful. This blog explores how you can enable users to evaluate the quality of your LLM output and how to improve it iteratively based on user feedback.
Key Metrics for Evaluating LLM Outputs
To properly assess the quality of LLM outputs, we need to focus on several key metrics:
- Relevance: Does the output directly address the input query? How well does it match the context and intent of the request?
- Accuracy: Is the content factually correct? LLMs can sometimes generate plausible but incorrect information, making accuracy a top priority.
- Coherence: Is the output logical and well-structured? Coherence ensures that the response flows and makes sense.
- Fluency: The linguistic smoothness of the output—whether it feels natural and human-like.
- Diversity: Especially important for creative tasks, does the model produce varied outputs without repetition?
- Toxicity and Bias: Mitigating harmful or biased content is critical, as unchecked LLMs may generate inappropriate or skewed responses.
The User-Centric Approach to Evaluating LLMs
While evaluating LLMs using internal tests is important, the real test of an LLM's quality comes from its users. User feedback is invaluable in understanding how well the model performs in real-world applications. The following are key reasons why your users should play a pivotal role in evaluating your LLM outputs:
- Context-Specific Needs: Every use case has its unique requirements. Users can provide feedback tailored to the specific context in which they use your LLM, giving insights that aren't always captured in generic testing.
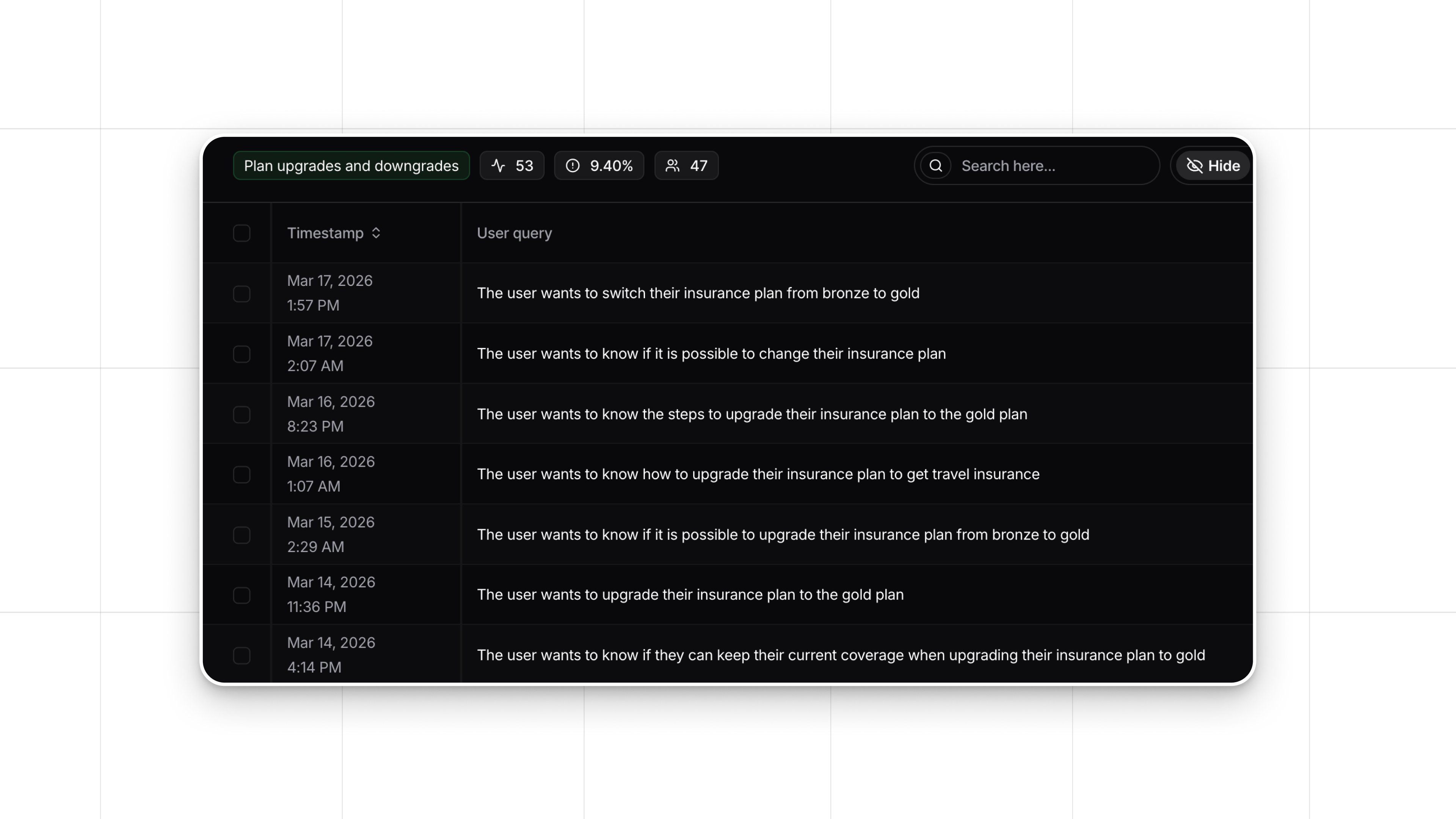
- Real-World Edge Cases: Users will often surface edge cases that were not anticipated during initial development, helping you identify gaps and areas for improvement.
- User Satisfaction: In the end, the utility of an LLM is determined by its users. Gauging user satisfaction through feedback is essential for understanding whether the outputs meet their expectations.
Picking the Right LLM & Involving Users Early
Selecting a well-performing LLM from the outset is important, but perfection isn’t expected immediately. Instead of spending too much time refining your model in a vacuum, get real users involved as early as possible. Their feedback will be invaluable in guiding improvements.
This brings us to an important distinction: LLM-as-a-judge versus user-as-a-judge.
- LLM-as-a-judge: In this approach, automated evaluations such as BLEU scores or perplexity metrics are used to gauge quality. While useful for benchmarking, these metrics often fall short of capturing the nuances of user experience, as ultimately you have an LLM judging an LLM.
- User-as-a-judge: Here, human feedback takes the center stage. Users interact with the model, and their feedback—whether direct (through ratings) or indirect (through behavior)—is used to evaluate output quality.
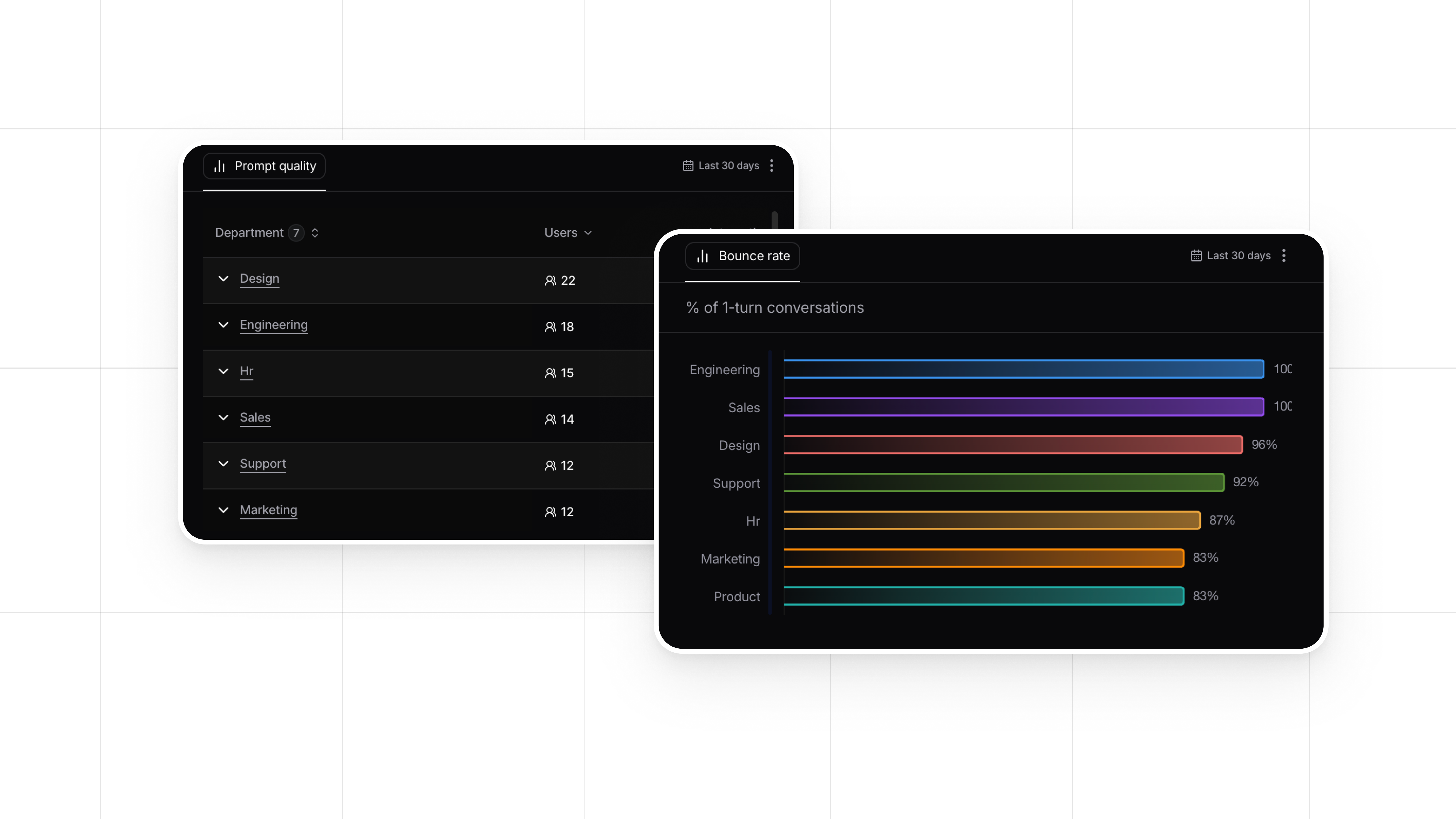
How Nebuly Facilitates LLM Output Evaluations
Nebuly is a platform that integrates user feedback directly into the evaluation process of LLMs. With Nebuly, you can:
- Collect Real-Time User Feedback: Whether through ratings, comments, or engagement metrics, you can gather insights into how users are interacting with your LLM.
- Analyze User Experience: Nebuly offers tools to track and analyze user feedback, making it easy to identify common pain points, low-quality outputs, and opportunities for improvement.
- Iterative Testing and Improvement: Using the data gathered, you can continuously tweak and fine-tune your LLM’s performance, ensuring that it evolves based on actual user needs. Nebuly helps you manage this feedback loop efficiently, accelerating the time-to-value for your LLM.
Conclusion
Evaluating LLM outputs is an ongoing process that hinges on user involvement. While internal metrics like accuracy and fluency provide a foundation, the true measure of success lies in how well your users interact with and value the model's output. Platforms like Nebuly streamline the evaluation process by facilitating user feedback collection and analysis, helping you refine and optimize your LLM’s performance iteratively.
By adopting a user-centered evaluation process, you can ensure your LLM delivers meaningful, high-quality results for your specific use case. If you'd like to learn more about Nebuly, please request a demo here.