Customizing LLMs to specific use cases is critical for delivering precise, relevant, and efficient outputs. Whether you're building a customer service chatbot, a recommendation system, or any other LLM-powered product, there are three primary strategies for enhancing model performance: fine-tuning, prompts, and retrieval-augmented generation (RAG). Each of these approaches plays a vital role in adapting LLMs to meet specific needs, helping businesses continuously improve how the model performs and, ultimately, enhancing the user experience.
Understanding the differences between these techniques—and knowing when to use each—can significantly affect the success of your LLM-powered product. Let's dive into what fine-tuning, prompts, and RAG are and explore how they can shape your model's behavior and performance.
Fine-Tuning, Prompt Engineering, and RAG: Key Concepts
- Fine-Tuning: Fine-tuning is the process of taking a pre-trained LLM and adapting it to a specific task or domain by training it further on your own dataset. This allows you to customize the model’s behavior more thoroughly, making it more adept at handling niche tasks, terminology, or knowledge areas that may not be well-covered by the base model. Fine-tuning is typically more resource-intensive as it requires additional data, computational power, and expertise in model training.
- Prompt Engineering: Prompting or better called System Prompting in this context, refer to the way you structure your inputs to guide the model toward generating a desired output. By carefully crafting the way a question or task is presented, you can influence how the LLM responds, even without altering the model itself. System prompting is a lightweight and fast way to improve the model’s performance, as it requires no additional training or computational resources, making it an accessible method for many use cases.
- Retrieval-Augmented Generation (RAG): RAG combines LLMs with external knowledge sources. When a query is posed to the model, RAG allows the system to retrieve relevant information from a database or document store and feed it back into the model to generate a more accurate response. RAG is particularly useful for ensuring the LLM has access to up-to-date information or domain-specific knowledge that might not be fully captured during its original training.
Fine-Tuning vs. Prompts vs. RAG: Complexity and Use Cases
These three techniques—fine-tuning, prompting, and RAG—differ not only in their implementation complexity but also in when and how they should be used, depending on the stage of your LLM development and the problem you’re trying to solve.
- Fine-Tuning:
- Complexity: Fine-tuning is the most complex option because it requires additional data collection, model training, and testing. You’ll need access to a large, high-quality dataset relevant to your use case and enough computational power to retrain the model. This method is also the most expensive and time-consuming.
- Use Case: Fine-tuning is ideal when your LLM needs to consistently perform a specific task, like understanding domain-specific language (e.g., legal or medical terminology), handling specialized queries, or adhering to particular standards. It’s usually more beneficial in later stages of development when you have a clear idea of the precise customizations required.
- Prompts:
- Complexity: Prompting is the simplest and least resource-intensive approach. By refining how you ask questions or give instructions to the model, you can significantly influence its output without any need for additional training. This can be done instantly, and the results can be evaluated in real time.
- Use Case: Prompts are most effective when you're experimenting with an LLM in the early stages or when you need quick and easy customizations for a variety of tasks. It’s ideal for when you don’t have the resources or time to fine-tune the model, but you still want to guide its behavior for better results.
- RAG:
- Complexity: RAG falls between fine-tuning and prompting in terms of complexity. While it doesn't require retraining the model, you do need to set up a system to retrieve relevant information from external databases or sources, which can be technically complex.
- Use Case: RAG is a powerful solution when your use case requires the model to have access to real-time, up-to-date information or highly specialized content that isn’t part of the LLM’s training. It’s ideal for applications like customer service, where you need the LLM to pull from an evolving knowledge base.
Impact on Customer Experience
The approach you choose—fine-tuning, prompting, or RAG—directly influences the overall customer experience when users interact with your LLM-powered product. Each method can help improve how well the model understands user queries, the relevance of its responses, and the user’s overall satisfaction. However, making changes to your model also requires careful evaluation of its impact on user experience.
For instance, fine-tuning can lead to a more personalized experience, but improper tuning may result in overfitting or loss of generalization, leading to user frustration. On the other hand, prompting provides quick adaptability but may not deliver consistency over time. Similarly, RAG can improve accuracy but could introduce latency if not implemented efficiently.
To measure the impact of these changes, it’s essential to evaluate user satisfaction after each iteration. How do users react to the new behavior? Are they more satisfied with the responses, or do they encounter issues that didn’t exist before?
Improving LLM Performance and User Experience Iteratively
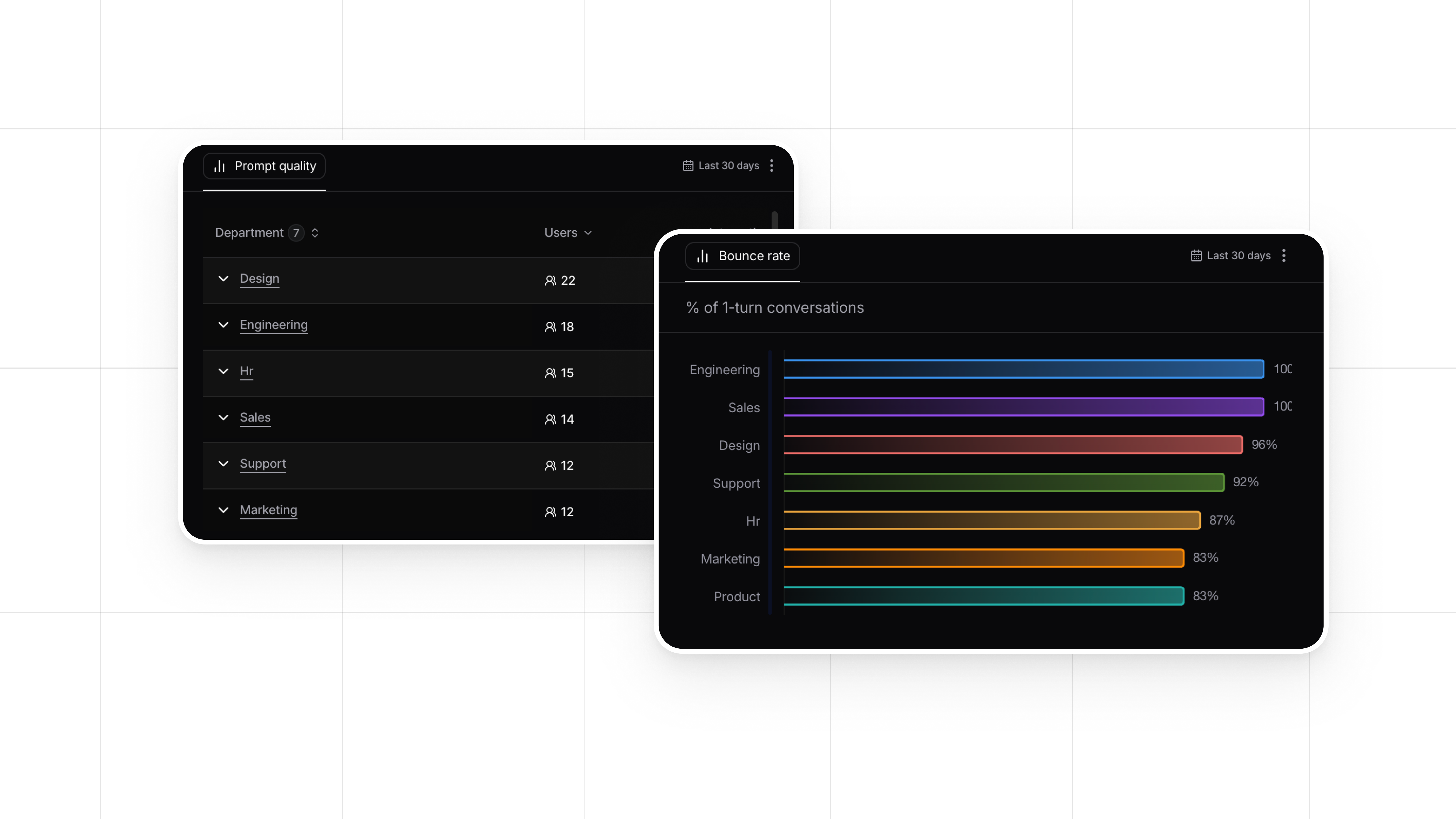
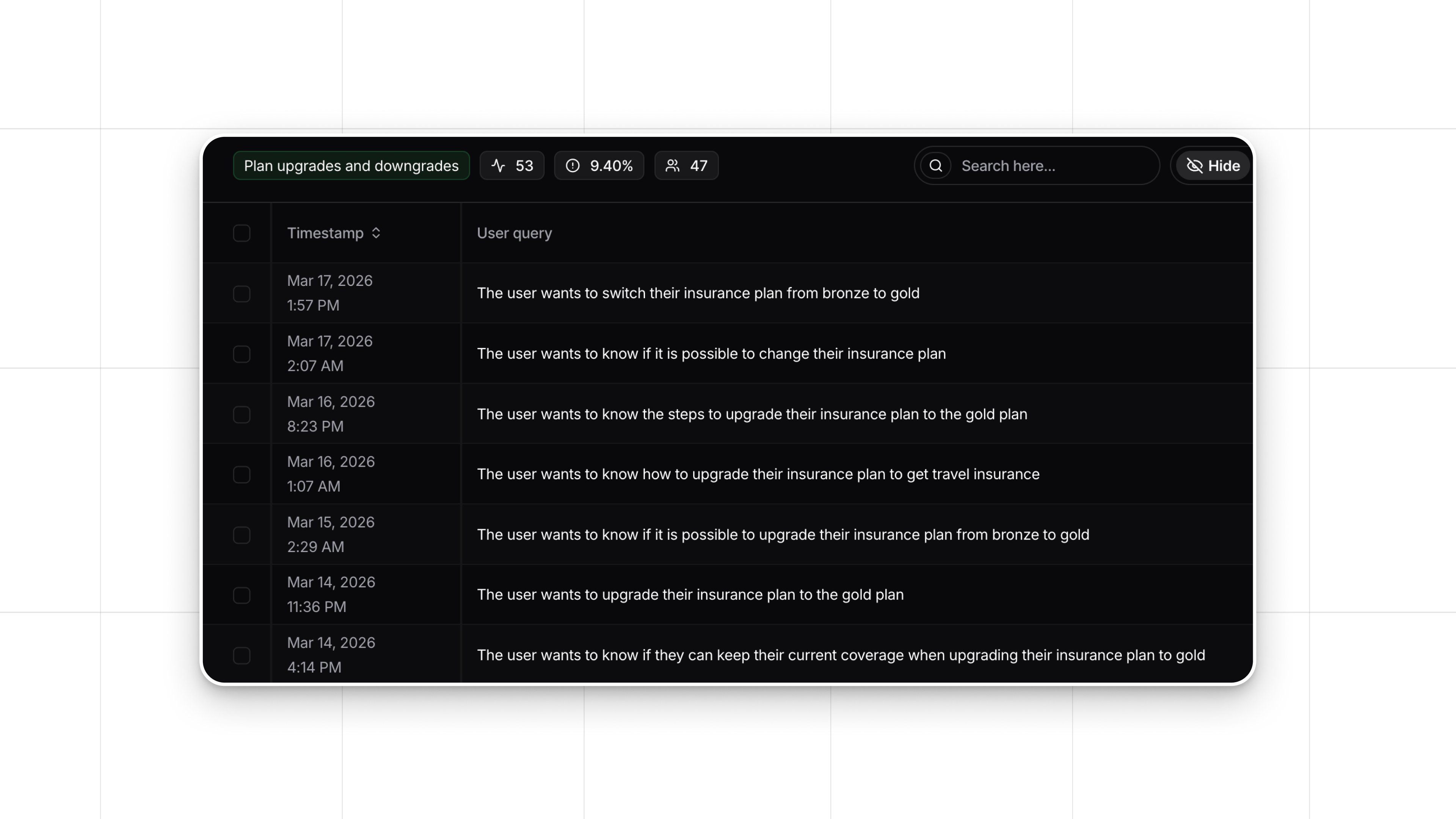
For companies deploying LLM-powered products in production, experimenting with fine-tuning, prompting, or RAG can be challenging. Nebuly makes it easier to experiment and optimize these approaches by offering tools for A/B testing and user satisfaction tracking. With Nebuly, you can:
- A/B Test Changes: Experiment with different techniques—whether it’s fine-tuning, adjusting prompts, or implementing RAG—by testing them with a selected group of users. This allows you to measure the direct impact of each change in real-time.
- Monitor User Experience: Nebuly’s analytics tools help you track user satisfaction and engagement after each change, ensuring that the model’s performance aligns with user expectations.
- Optimize Continuously: Nebuly enables you to continuously refine your LLM by providing insights into how each adjustment affects the user experience, making it easier to identify what works and what needs improvement.
By leveraging Nebuly, you can confidently iterate on your LLM, ensuring that every change leads to an improved model and a better overall user experience for your customers. If you'd like to learn more about Nebuly, please request a demo here.