Large Language Models (LLMs) have become the backbone of advanced natural language processing, enabling machines to generate and comprehend human-like text. At the core of these models are LLM parameters—key elements that dictate how these AI systems function. In this blog post, we will break down what LLM parameters are, how they interact with other model components, and the steps to build and refine LLMs. We will also explore how real-world feedback and platforms like Nebuly can enhance LLM performance.
What Are LLM Parameters?
LLM parameters are the internal settings that guide how a model processes and generates text. Think of them as the intricate dials and levers that adjust the model’s language capabilities. They include:
- Weights: These parameters define the strength of connections between different parts of the model. Weights adjust how the model interprets and prioritizes various aspects of the input data, enabling it to recognize patterns and relationships within the language.
- Biases: Biases are initial values that influence the model’s predictions. They act as baseline adjustments, helping the model form early judgments about data before it undergoes extensive training.
- Embedding Vectors: These are numerical representations of words that allow the model to understand and process textual data. Embedding vectors capture the semantic meaning of words, enabling the model to generate contextually appropriate responses.
The Role of Parameters in Model Complexity
The number of parameters in an LLM directly impacts its complexity and capabilities. Larger models with billions of parameters can capture more intricate patterns and generate more nuanced text. However, this increased complexity comes with trade-offs, including higher computational costs and greater risk of overfitting.
For example, Meta has their Llama 3.1 family of LLMs and have models ranging from 8B to 70B to a massive 405 Billion parameters, allowing developers to choose a smaller models that are more efficient or larger with higher level of performance across diverse applications.
Building and Refining LLMs: Pre and Post Production
Pre-Production Steps
- Model Architecture Design: Choosing the right architecture, such as Transformers, determines how the model processes and learns from data. The architecture influences how parameters like weights and biases are utilized. For instance, attention mechanisms within Transformer models rely heavily on parameter settings to focus on relevant parts of the input text.
- Data Collection and Preparation: Gathering and curating datasets is crucial for training. The quality and diversity of the data affect how parameters are adjusted during training. Well-prepared data helps in setting appropriate parameter values that lead to better model performance. Embedding vectors are particularly impacted by the nature of the training data, as they encode textual tokens into numerical formats.
- Hyperparameter Tuning: Adjusting hyperparameters such as learning rates and batch sizes is essential for optimizing model training. These hyperparameters influence how parameters like weights and biases are updated during training. Effective tuning can lead to more efficient learning and better overall model performance.
Pre- and Post-Production Steps
- Fine-Tuning: After initial training, the model may be fine-tuned on specific tasks or datasets to enhance its performance in particular areas, such as customer support or technical writing.
- Evaluation: Testing against benchmarks helps assess the model's effectiveness. This evaluation identifies strengths and weaknesses, guiding further improvements.
Post-Production improvements with Real User Feedback
Real-world performance is the ultimate test of an LLM’s capabilities. Continuous improvement based on user feedback is vital for maintaining and enhancing model performance. Here’s how to effectively incorporate user feedback:
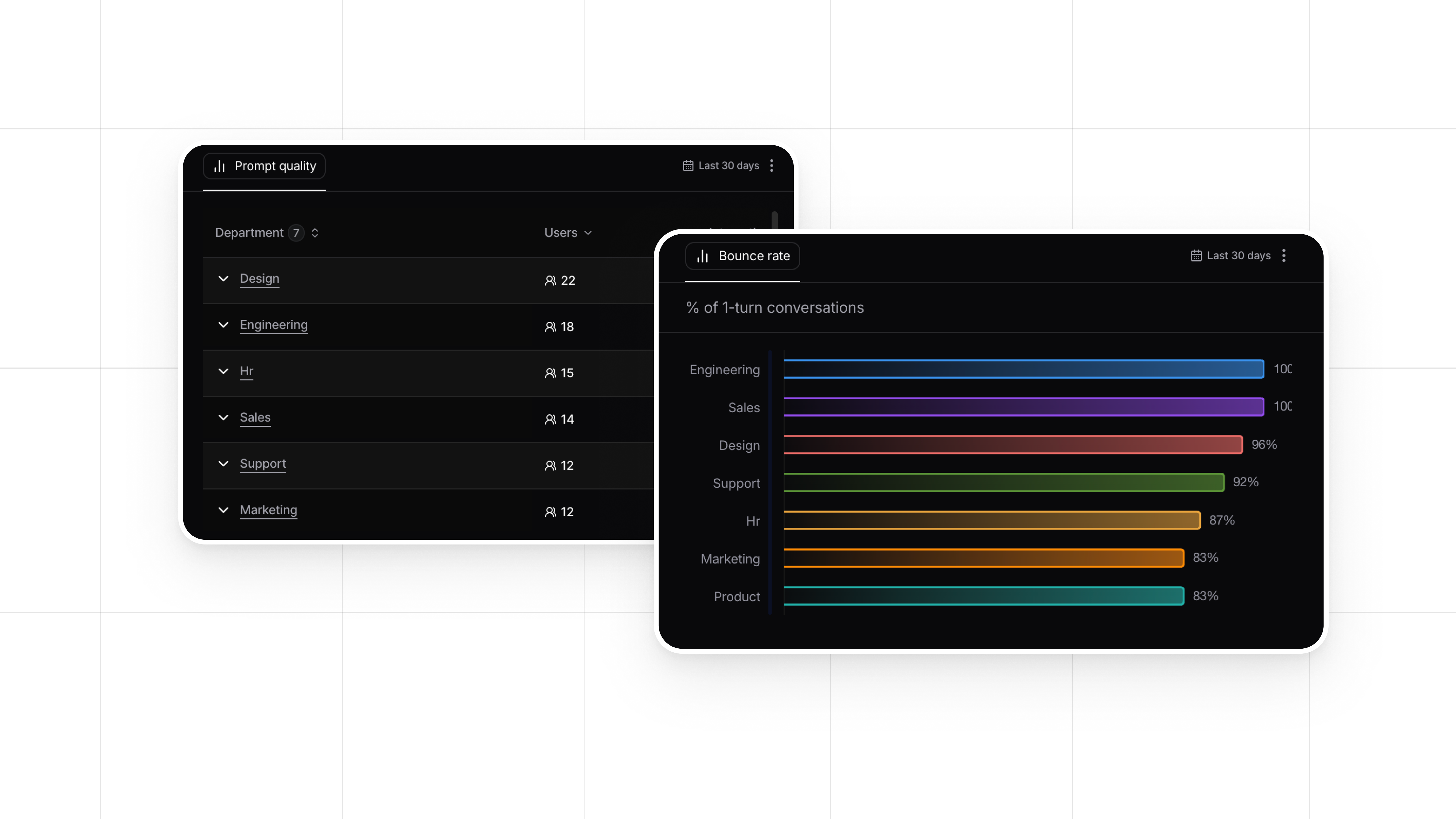
- Performance Monitoring: Regularly track the model’s interactions and performance to identify any issues or areas for improvement.
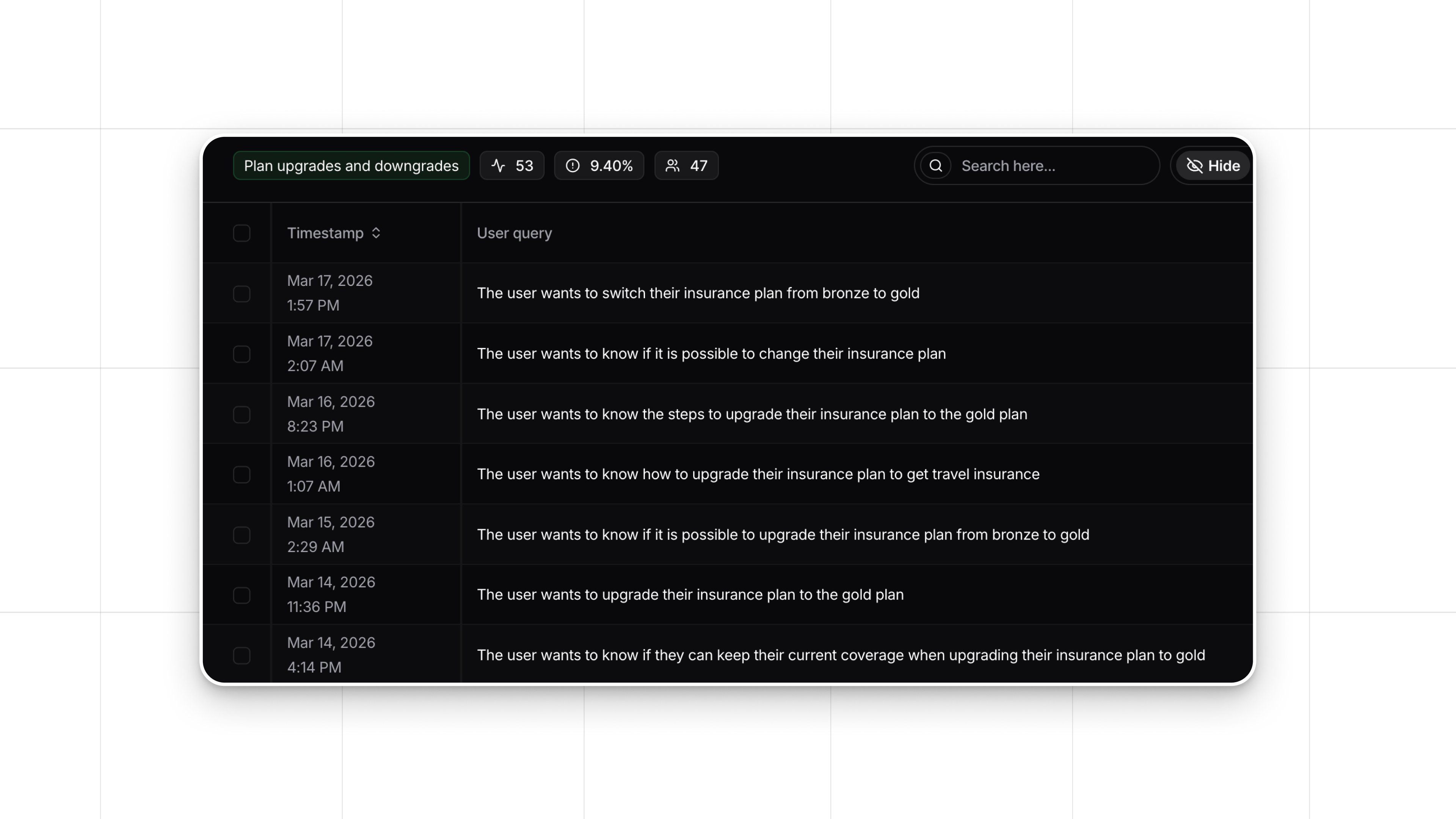
- Feedback Collection: Gather explicit and implicit feedback from users regarding the model’s responses and behavior. This feedback helps pinpoint problems and areas where the model may need adjustment.
- Iterative Refinement: Use the feedback to make iterative improvements. This might involve using system prompts, adding new RAG sources, or fine-tuning to better align with user expectations.
Nebuly: Elevating LLM User Experience
Nebuly is a software platform designed to enhance the user experience with LLMs. It offers tools for analyzing user feedback, and implementing improvements efficiently. By leveraging Nebuly, organizations can ensure their LLMs remain effective, responsive, and aligned with user needs. If you're interested in uncovering user insights that improve your LLM, we'd love to chat. Please request a demo meeting with us HERE.
Conclusion
LLM parameters are crucial to understanding and harnessing the full potential of these powerful models. By comprehending how parameters interact and impact model performance, and by employing robust methods for ongoing improvement—including platforms like Nebuly—organizations can optimize their LLMs for better accuracy and user satisfaction.